在設計資料表的過程中索引的設計會跟查詢效率有直接的關係,隨著數據量的增加一條查詢SQL語句有無吃到index對執行上的效率差異是明顯可見的。
套用索引最常看到的比喻,index(索引)就像是書的目錄。
有了目錄你就能根據上面定位好的頁數紀錄去找到對應資料,相反的沒有這些目錄,你就得慢慢的去找到你要的內容(全表掃描)。
MySQL數據路徑底下的資料庫檔案內可以看到,InnoDB儲存資料庫資料有3個檔案分別為:
db.opt
.opt檔紀錄該資料庫預設字符集編碼和字符集排序規則。
table_name.frm
.frm檔存放這個表的相關資料(表結構定義)資訊。
table_name.ibd
.ibd檔存放這個表的資料與索引內容。
InnoDB表資料檔案本身就是按B+Tree組織的主索引結構,資料與索引的儲存以Clustered Index來聚集組織。
InnoDB將索引分成Cluster Index & Secondary Index
聚集索引 Clustered Index (primary Index) 是什麼?
先看MySQL如何選擇Clustered key規則:
建表時有primary key,選primary key。
沒有primary key的話,選第一個not null的unique key。
以上都沒有,產生一個auto increment的隱藏欄位做clustered key。
每個表只會有一個Clustered Index(表紀錄只能用一種物理順序存放)
InnoDB採用B+Tree來作為組織實現儲存資料的主索引結構,用以下圖來解釋~
leaf node(葉節點) 真正存資料的地方
儲存主鍵值的row data和一個指向相鄰節點的指標。
非葉節點
儲存key的值和指向child node的指標,作用在定位到具體的紀錄位置。
左閉合區間查詢
查詢資料採用左閉合區間查詢。 ex.[a,b) =包含a但不包含b的區間範圍。
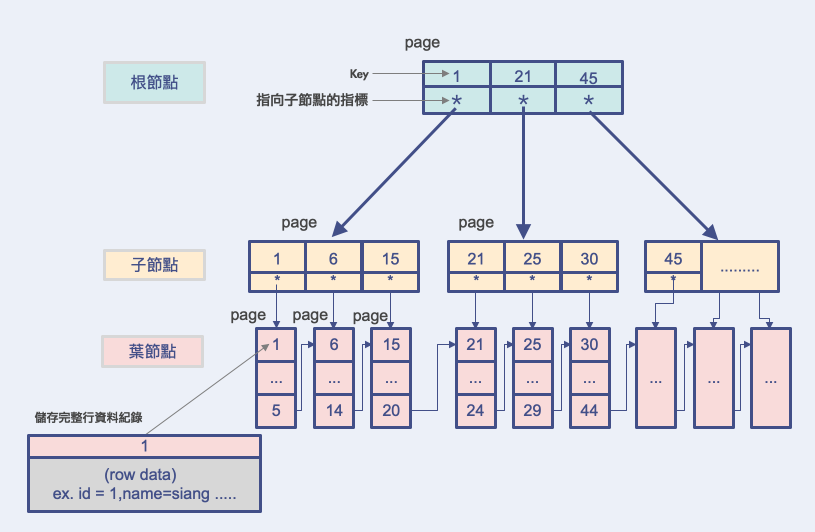
運作邏輯:
還記得在前面InnoDB架構介紹時有提到資料與索引都是儲存在磁碟中的,要使用的話會先將資料所在的page載入內存中才進行動作。內存和磁盤以page為單位交換資料!!
那問題來了當數據量大的時候,索引檔案的大小可能會很大,總不能直接用一次性的載入memory,所以在資料查詢時會分多次磁碟IO逐一加載disk page(對應B+tree的node),將索引相關資料分批載入memory。從根節點開始逐層索引到葉節點後返回資料。
Page
InnoDB磁盤管理的最小儲存單位。page default: 16KB <-最多存放16KB的資料
針對B+Tree架構整理以下特點:
引用官方敘述
If index records are inserted in a sequential order (ascending or descending), the resulting index pages are about 15/16 full. If records are inserted in a random order, the pages are from 1/2 to 15/16 full.
可見存放資料時不會把全page空間都用完,而是保留一部分做日後的新增更新。紀錄循序插入page維持在約15/16滿,紀錄亂序插入的話page維持在約1/2~15/16滿。
上面提到資料會按照主鍵值順序存放,對於有序主鍵值(ex.自增ID)來說,當我們新增一筆資料時,mysql根據主鍵值將其插入當前索引節點的後續位置,不需做額外的搬動,當page到達(15/16)後,開一個新page存放資料。那當使用(值不重複的隨機值PK)就會遇到需要插入到現有page的某個位置,造成page之間的資料搬動,增加效能上的開銷。
以上圖B+tree結構舉例來說,當我要查找ID=26的這筆資料
第一次IO:
第二次IO:
第三次IO:
看完以上內容對於InnoDB主索引架構有了基本的認識,有一個部分在這篇我沒提到,有興趣可以去看看~就是MySQL為何選擇了B+Tree? B+tree & B-tree差異在哪?
像是針對只有葉節點才存放資料的特性可以比對出以下差異~
(B+tree)在子節點上因為沒有存放資料,所以在一個page 16K限制下相比(B-tree)能存放更多的key,B+tree磁碟讀寫更好,一次的IO載入資料量更多。
(B+tree) key相關的資料只存在葉節點上,保證查詢的穩定,都要到達葉節點後才拿得到資料。而(B-tree)在子節點中存放資料,命中key就能拿到資料。
明天來介紹Secondary Index~

